Dataset details
The dataset consists of images collected in an unstructured road scenario, driving in adverse weather conditions of rain, fog, lowlight and snow. Each individual RGB image has a more detailed near-infrared image (NIR) captured simultaneously. The images are collected using JAI FS-3200D-10GE camera. The dataset comprises 5000 images, manually selected to represent various adverse weather scenarios, including rain, fog, low light, and snow. Each RGB image also has a paired NIR image to provide image enhancement. Each image is densely annotated at the pixel level for semantic segmentation, utilizing a label set with a hierarchical structure consisting of 7 labels at level 1 and 30 labels at level 4.
Test DatasetIDD-AW Dataset page
Download here
Summary
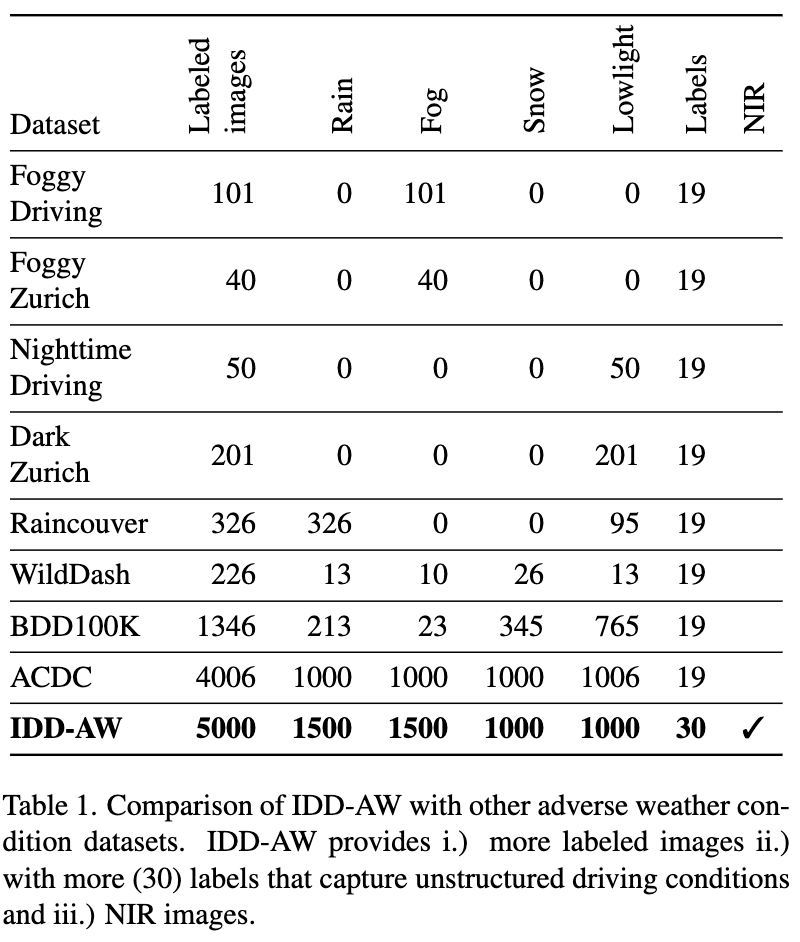
Dataset Comparison
- IDD-AW provides more labeled images compared to other datasets.
- IDD-AW includes adverse weather conditions such as rain, fog, snow, and lowlight.
- IDD-AW offers a diverse range of labeled conditions, including NIR images, capturing unstructured driving environments.
- IDD-AW features 30 labels, providing comprehensive coverage of driving scenarios.
- Other datasets, such as ACDC, BDD100K, and WildDash, focus on specific adverse weather conditions or driving scenarios.
Label Heirarchy and Statistics
Pixel-wise Comparison:
- IDD-AW has more pixels compared to ACDC.
- The pixel counts are normalized by resolution and the number of images in the datasets.
Traffic Participants Instances Count:
- IDD-AW has more instances per image of traffic participants (TP) than ACDC.
- Traffic participants include all vehicles and living things that represent unstructured traffic.
- There are over 300 images in IDD-AW with more than 20 instances of TP, while ACDC has only around 10.

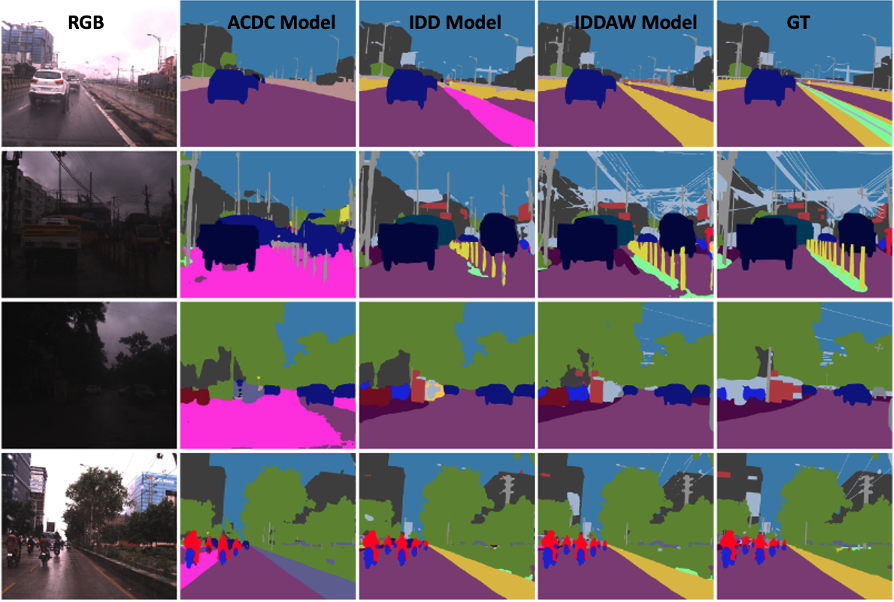
Examples