IDD117K Detection Dataset
The newly released IDD-117K dataset comprises of two parts:
- IDD-Detection, released (earlier in 2018), and
- IDD-95K-Detection, recently added.
IDD-Detection dataset comprises of three partitions: 31569 for train (images and annotation), 10225 for validation (images and annotation) and 4794 for test (images).
IDD-95K-Detection dataset comprises of three partitions: 65328 for train (images and annotation), 9977 for validation (images and annotation) and 19850 for test (images).
This comprehensive dataset IDD117K-Detection provides: 96897 for train (images and annotation), 20202 for validation (images and annotation), and 24644 for test (images); i.e., a total of 117,099 images for train & validation.
The annotations for test images, from both parts are not released in public.
IDD117K Detection Dataset
The IDD95K dataset is an extensive object detection dataset comprising 95,155 images with corresponding annotations provided in JSON formats. The dataset is specifically designed for training and evaluating object detection models across various Indian driving scenes.

Dataset Distribution
The dataset is divided into three subsets: training, validation, and testing, following a 70:10:20 ratio. The split statistics are as follows:
- Training Set: 65328 images
- Validation Set: 9977 images
- Test Set: 19850 images
Classes:
The dataset includes a diverse set of 13 classes mainly traffic participants from person and rider to traffic signs, pole and even vehicle fallback. Each of these classes are most commonly occurring on Indian unstructured driving scenes.
The list of classes are as follows:
- Person
- rider
- - bicycle
- autorickshaw
- car
- truck
- bus
- pole
- traffic light
- traffic sign
- vehicle fallback
- ego vehicle
Annotations
The IDD95k dataset contains a total of 1,706,768 annotated instances across all classes. Each instance is precisely labeled, facilitating accurate training and evaluation of object detection models.
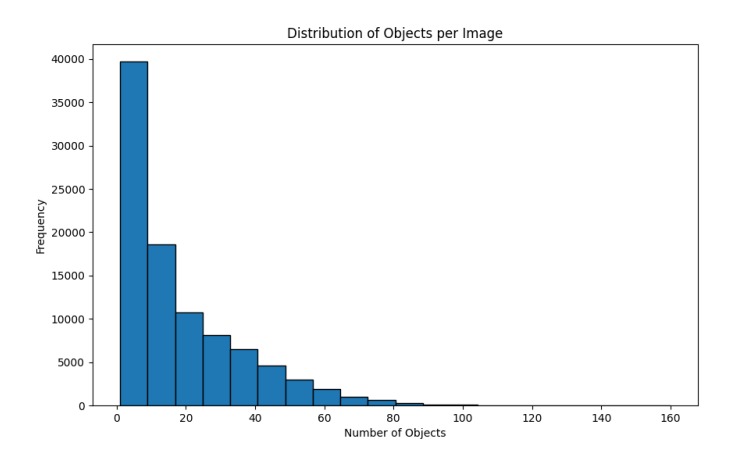
Distribution Statistics
Objects per Image
The dataset has a varying number of objects annotated per image, providing a robust distribution for model training.
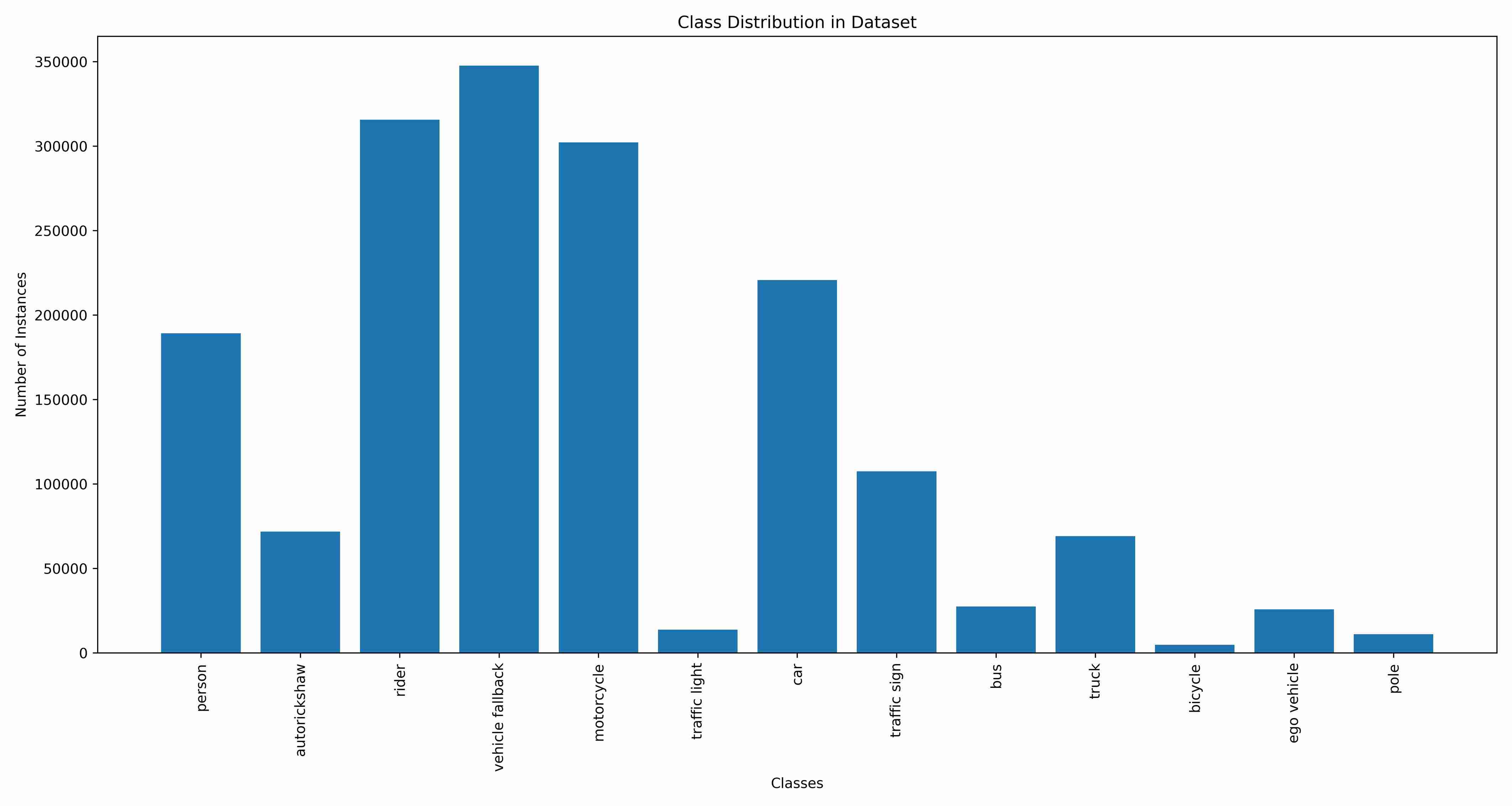
Class Distribution
The distribution of objects across different classes has been visualized to give insights into the dataset's balance and skewness. These plots provide crucial information for understanding class imbalances, which is essential for model tuning and evaluation.
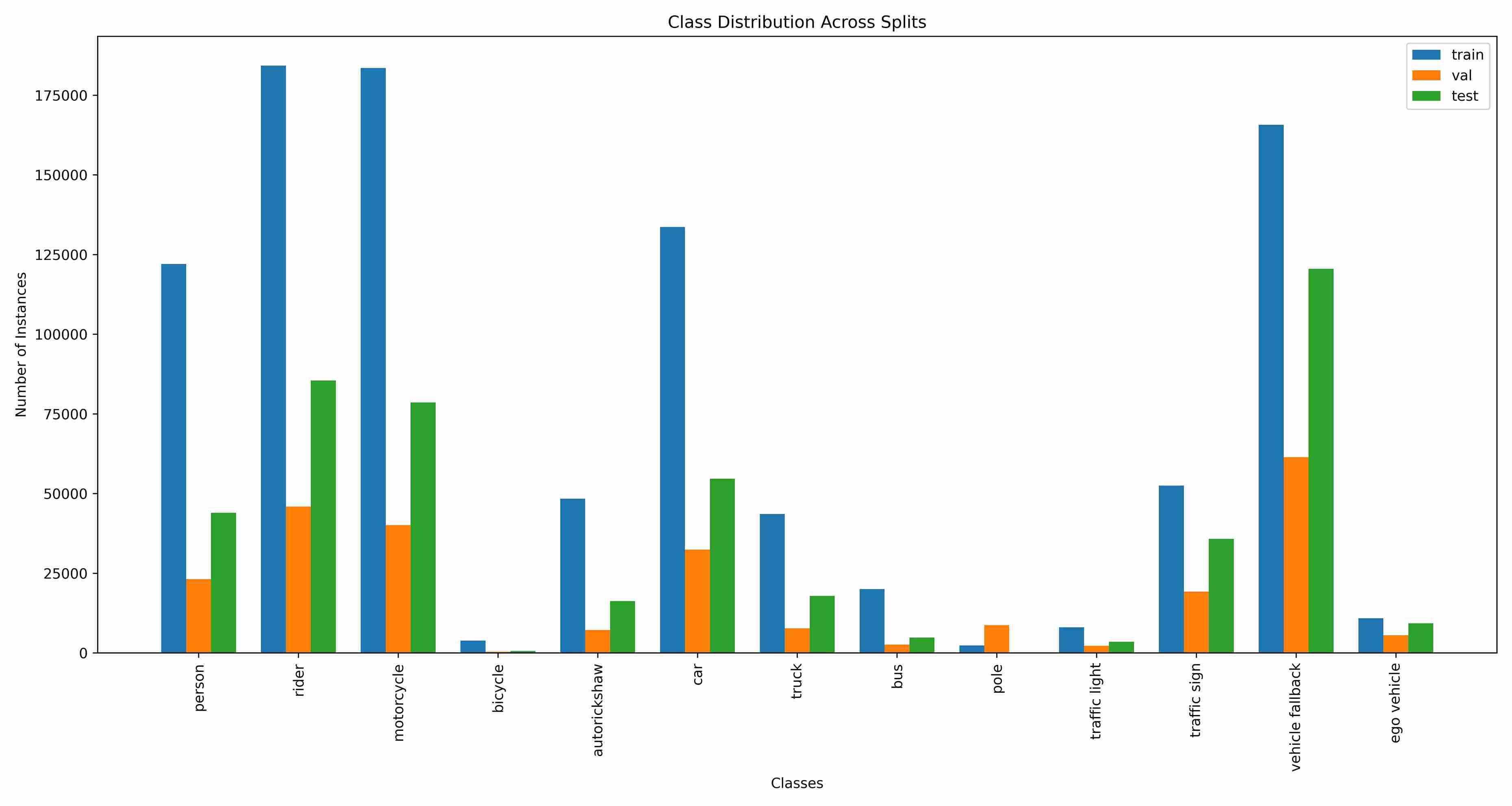
Classwise Distribution in Train, Test, and Validation Sets
The dataset maintains a consistent class distribution across the training, validation, and test sets. Detailed plots are available to illustrate these distributions, aiding in the analysis of model performance across different subsets.
Dataset Link: https://https://datafoundation.iiit.ac.in/smart-mobility
The IDD100k dataset is an extensive object detection dataset comprising images with corresponding annotations provided in JSON formats. The dataset is specifically designed for training and evaluating object detection models across various Indian driving scenes.