IDD-X: A Multi-View Dataset for Ego-relative Important Object Localization and Explanation in Dense and Unstructured Traffic
The development of reliable and efficient intelligent vehicle systems is dependent on its capability to understand the influence of road and traffic conditions on its own driving actions. This is particularly challenging in developing countries such as India where traffic situations are often dense and unstructured with heterogeneous road occupants. Existing benchmarks, predominantly geared towards structured and sparse traffic scenarios, fall short of capturing the complexity of driving in such environments.
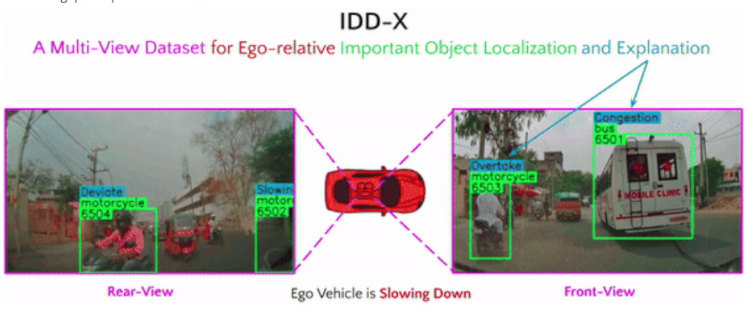
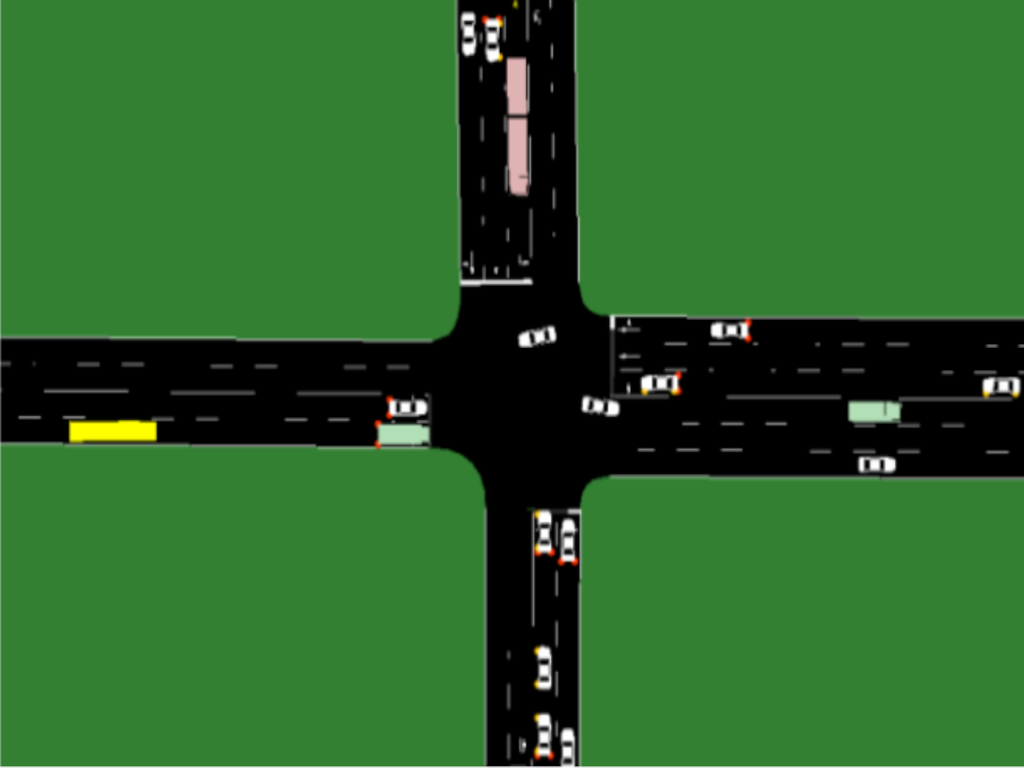
A large-scale dual-view (front and rear) driving video dataset focusing on explainable driving decision-making in complex traffic scenarios. With 697K bounding boxes, 9K important object tracks, and 1-12 objects per video, IDD-X offers comprehensive ego-relative annotations for multiple important road objects covering 10 categories and 19 unique explanation label categories observed in unstructured, heterogeneous and dense traffic environments. The Bird Eye View illustration of explanations for important road objects in different traffic situations is depicted below.
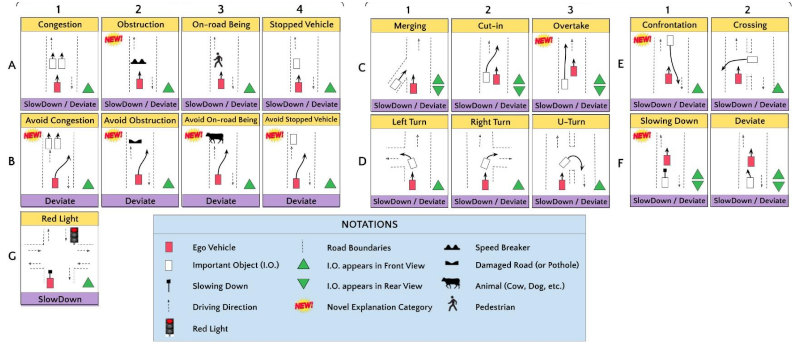
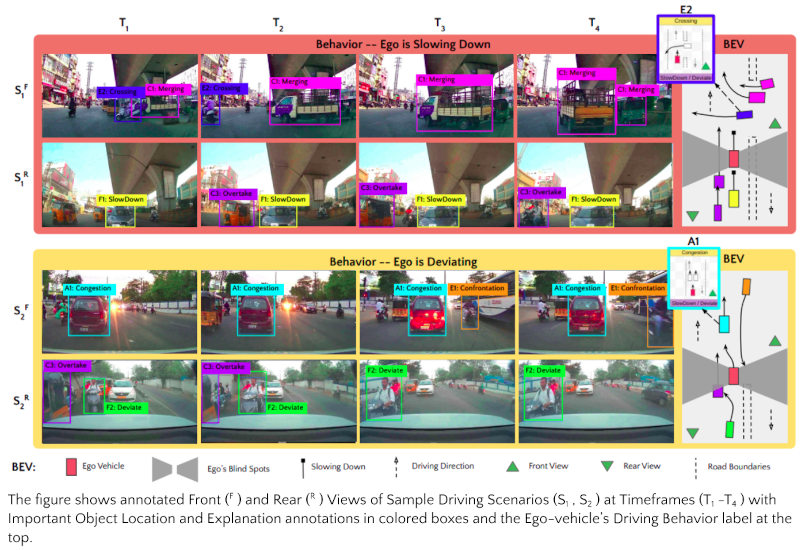
IDD-X DATASET ANNOTATIONS
The dataset provides the following three types of annotations:
- Ego Vehicle’s Driving Behavior (e.g. Slowing Down)
- Important Objects’ Track and Category (Colored Boxes)
- Important Objects’ Ego-relative Explanation Category (Colored Box Labels)
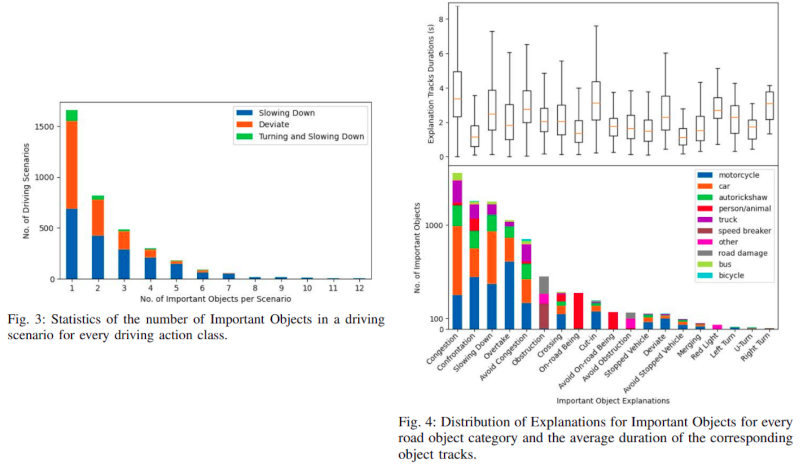
DATA STATISTICS
The distribution of the number of Important Objects and their Explanations with the temporal duration is shown in the following figures:
APPROACH
We introduce custom-designed deep networks for (I) Multiple Important Object Track Identification, and (III) Important Object Explanation Prediction with (II) Ego-Vehicle's Driving Behavior Recognition.
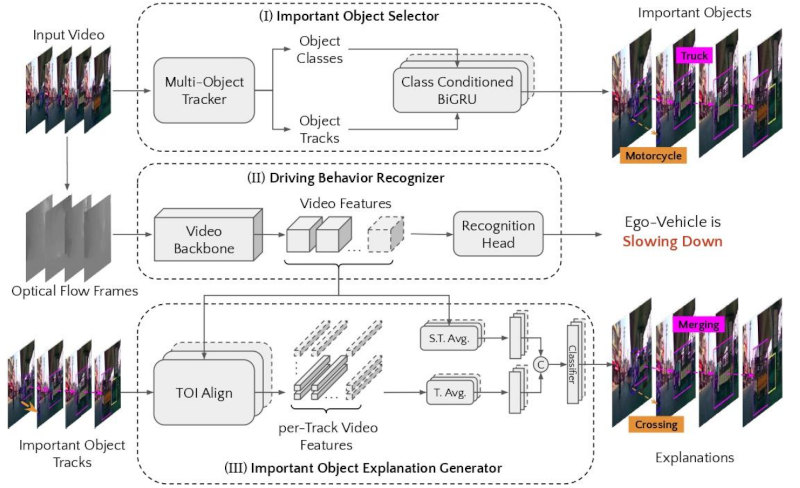
RESULTS
We establish new benchmarks using our custom-designed deep networks for the proposed tasks (I), (II), and (III) in dense and unstructured traffic scenarios. All values are reported in %.
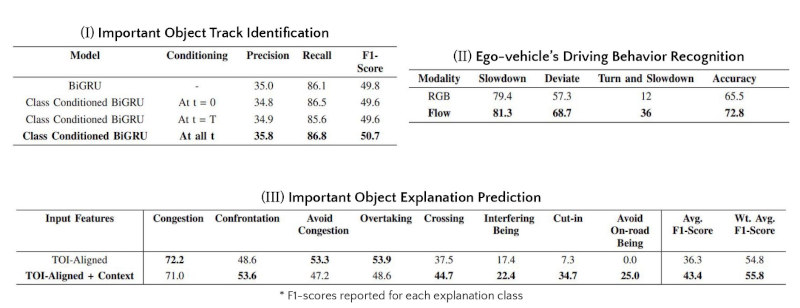
- The Object’s Class information conditioned throughout its trajectory improves performance.
- Optical Flow modality as input to video model gives best performance on IDD-X.
- Video Features (Context) along with per-Track Features gives best average and overall performances.
CONCLUSION
Overall, our dataset and prediction models can serve as a foundation for studying how road conditions and surrounding entities affect driving behavior in complex traffic situations.
This project is funded by the iHub-Data and Mobility at IIIT Hyderabad. We thank the data collection and annotation team for their effort.
Project Page : https://idd-x.github.io/
Paper : http://arxiv.org/abs/2404.08561
Dataset : https://insaan.iiit.ac.in/datasets/#idd_x
Code : https://github.com/chirag26495/IDD-X
Video : https://youtu.be/wtXng1S496w
Authors: Chirag Parikh, Rohit Saluja, C. V. Jawahar, Ravi Kiran Sarvadevabhatla